

Data science and big data analytics have rapidly transformed from an academic discipline into the central nervous system of modern American enterprise. Organizations across the United States combine rigorous statistical analysis with computer science to extract actionable intelligence from massive, complex datasets. You can see this shift clearly in how businesses utilize data-driven decision making to forecast demand, optimize supply chains, and personalize customer experiences. According to industry definitions from IBM, the field encompasses the entire data lifecycle, ranging from initial collection and cleaning to advanced predictive modeling and visualization. This comprehensive approach ensures that raw information becomes a strategic asset for long-term growth and competitive advantage in a digital economy.
The evolution of big data has necessitated a more sophisticated understanding of how information is processed and stored across distributed networks. Modern data scientists must navigate the complexities of unstructured data, which includes everything from social media posts to sensor readings from the Internet of Things. By applying advanced data mining techniques, professionals can uncover hidden correlations that were previously inaccessible to traditional business intelligence tools. This deep dive into information allows companies to move beyond descriptive analytics and toward prescriptive strategies that dictate future success. As the volume of global information continues to expand exponentially, the ability to synthesize these vast resources will remain a primary differentiator for market leaders.
Data science operates at the intersection of three distinct disciplines that require vastly different cognitive approaches and technical skill sets. Professionals in this field must balance mathematical rigor with practical software engineering and strong business acumen to produce reliable results. Missing any one of these foundational pillars often leads to predictive models that fail dramatically when deployed in real-world production scenarios. Modern machine learning algorithms further enhance these components by allowing systems to learn from experience without explicit programming. This synergy creates a powerful framework for solving the most complex problems facing global industries in the twenty-first century.
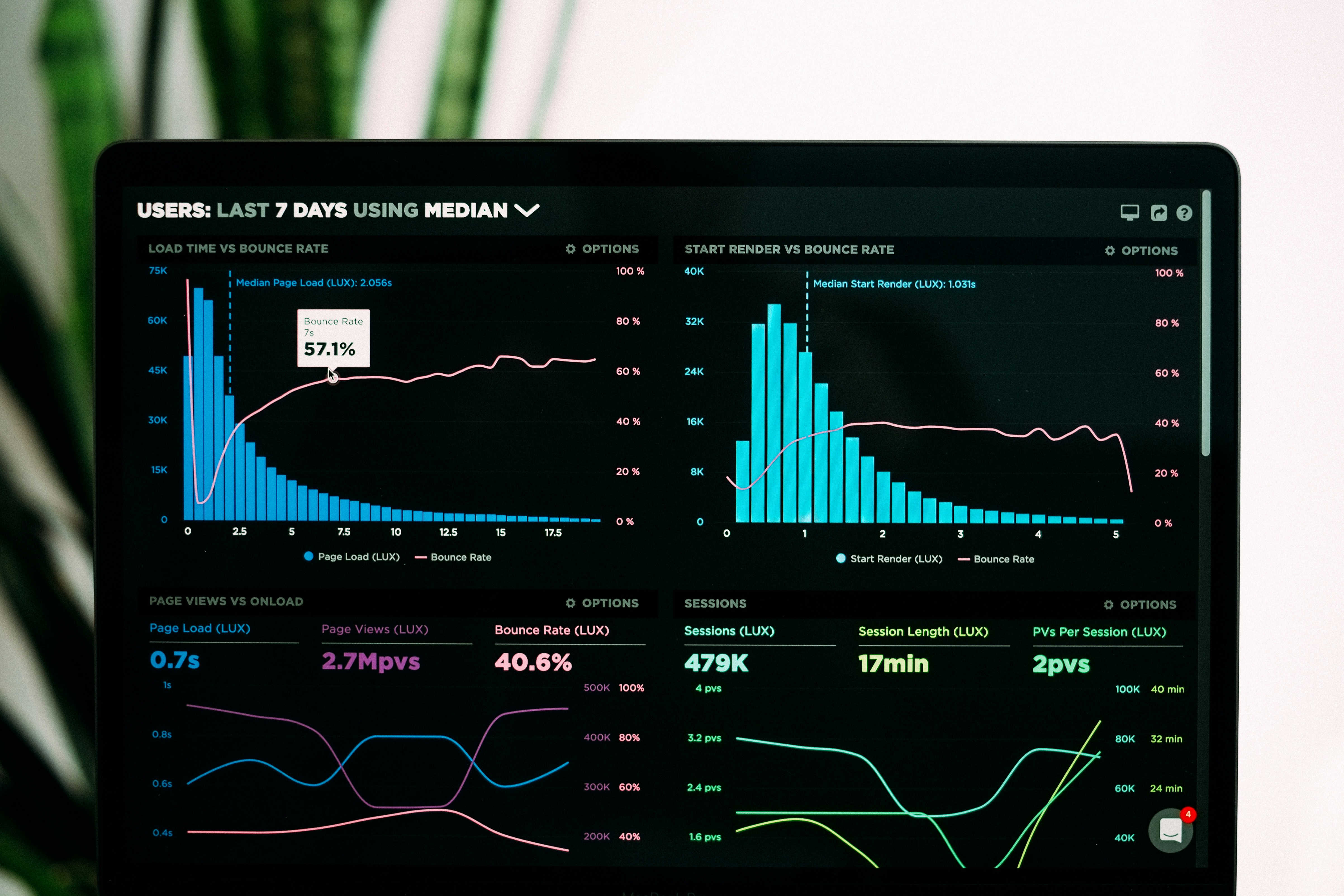
Statistical Analysis and Mathematical Foundations for Data Science
Rigorous mathematical foundations provide the necessary structural integrity for all advanced analytics and machine learning models used in industry today. Data analysts frequently use probability theory to understand complex distributions and identify significant statistical patterns within noisy, high-dimensional datasets. Furthermore, a firm grasp of linear algebra and multivariable calculus allows professionals to optimize these machine learning algorithms effectively for maximum performance. Beyond basic calculations, Bayesian statistics and hypothesis testing play a vital role in validating the reliability of experimental results before they reach stakeholders. Without these mathematical safeguards, organizations risk making expensive decisions based on coincidental correlations rather than true causation or statistical significance.
In addition to core mathematics, exploratory data analysis (EDA) serves as a critical first step in the statistical modeling process. This phase involves using descriptive statistics and visualization techniques to summarize the main characteristics of a dataset before formal modeling begins. By identifying outliers, missing values, and underlying structures, data scientists can ensure that their subsequent predictive modeling efforts are grounded in reality. EDA helps in formulating better hypotheses and selecting the most appropriate algorithms for the specific data at hand. Ultimately, the marriage of exploratory techniques and rigorous mathematical theory forms the backbone of any successful data science initiative.
Data Engineering and Programming: Building the Data Science Pipeline
Writing efficient software code allows you to scale theoretical mathematical models into robust, high-performance production environments safely and reliably. Python and R remain the dominant programming languages for statistical computing, data manipulation, and complex machine learning tasks. Software engineers also rely heavily on structured query language (SQL) to extract and transform raw information from vast relational databases and data warehouses. Additionally, data engineering has emerged as a critical sub-discipline focused on building the pipelines that transport information across an entire organization. These engineers ensure that data is available, clean, and formatted correctly for the data scientist to perform their analysis without technical friction.
The role of data engineering extends to managing the infrastructure required for big data analytics, such as Spark or Hadoop clusters. These systems allow for the parallel processing of massive datasets that would be impossible to handle on a single local machine. Modern data pipelines often incorporate automated testing and monitoring to ensure that the information flowing into models remains accurate over time. By treating data infrastructure as code, engineering teams can version control their pipelines and deploy updates with minimal downtime. This technical foundation is what enables data science to move from a laboratory setting into a scalable corporate environment.
Business Intelligence and Domain Expertise in Data Science
Technical coding skills hold incredibly little value without a deep understanding of the specific industry context and the underlying business goals. A model predicting customer churn requires fundamental knowledge of consumer psychology, market dynamics, and competitive pricing strategies within that specific sector. You must understand the underlying business problem thoroughly before attempting to solve it with complex mathematical algorithms or deep learning models. Effective data scientists act as translators who bridge the gap between technical possibilities and commercial realities for executive leadership. They must communicate their findings to non-technical stakeholders in a way that inspires confidence and drives immediate, data-driven action.
Key Takeaways
- Successful data science requires a balanced mix of mathematics, programming, and business knowledge.
- Python and R remain the foundational programming languages for modern corporate analytical environments.
- Technical models will fail quickly without a deep understanding of the specific industry context.
Maximizing ROI: How Data Science and Big Data Drive Business Value
Organizations invest heavy capital in advanced analytics because it consistently delivers highly measurable financial returns and operational improvements. According to research from McKinsey, companies utilizing advanced analytics report significant increases in their overall profit margins and market share. Corporate leaders no longer rely on pure intuition; they demand concrete, evidence-backed strategies for sustained revenue growth and risk mitigation. By leveraging big data, firms can identify hidden market opportunities and consumer trends that were previously invisible to traditional analysis methods.
Implementing predictive modeling allows corporate executives to anticipate rapid market shifts long before they actually occur in the physical world. Retailers analyze historical purchasing patterns and seasonal trends to optimize their physical inventory levels across thousands of nationwide locations. This proactive analytical approach reduces physical waste, minimizes storage costs, and maximizes revenue during incredibly busy seasonal shopping periods. Furthermore, real-time data processing enables companies to react to supply chain disruptions within minutes rather than days, maintaining continuity in volatile markets.
Data science also provides massive improvements in operational efficiency for logistics, manufacturing, and energy companies across the globe. Supply chain managers use complex routing algorithms to minimize fuel consumption and reduce delivery times for millions of packages daily. These incremental operational improvements compound rapidly to save large corporations hundreds of millions of dollars in annual operating expenses. Beyond cost savings, these efficiencies contribute to a more sustainable business model by significantly reducing the overall carbon footprint of the organization.
Pro Tip
Focus your initial data science projects on specific business problems that have highly measurable financial outcomes. This approach helps secure executive buy-in for future analytical investments and demonstrates immediate value through clear data-driven decision making.
Predictive Modeling and Data Visualization in Retail Analytics
Major national retailers constantly use customer transaction data to create highly personalized digital shopping experiences for their diverse user base. Recommendation engines analyze past individual purchases and browsing behavior to suggest complementary items, which significantly increases the average online order value. This data-driven personalization strategy builds long-term brand loyalty and drives highly profitable repeat business over an extended period of time. Effective data visualization tools like Tableau or PowerBI allow managers to monitor these trends through intuitive, interactive dashboards that simplify complex information.
Machine Learning for Fraud Detection and Anomaly Detection in Finance
Major American financial institutions process millions of credit card transactions daily, making manual human review physically impossible in the modern era. Machine learning models evaluate transaction characteristics in mere milliseconds to flag highly suspicious activity immediately for specialized security teams. This automated digital surveillance protects vulnerable consumers while saving major retail banks billions of dollars in fraudulent charges and legal fees annually. Advanced anomaly detection techniques can even identify new, emerging fraud patterns that have never been seen before by the system, providing a proactive defense against cybercrime.
Cloud Computing and Data Engineering: Building Your Data Science Infrastructure
Creating a truly robust analytical environment requires careful architectural planning and highly strategic technology investments from corporate leadership and IT departments. You need a centralized digital system that can process, store, and analyze vast amounts of varied unstructured information with high efficiency. A scalable modern infrastructure allows your entire engineering team to move from basic historical reporting to advanced predictive modeling and real-time analytics. This often involves the implementation of data lakes and data warehouses to manage the massive volume and variety of incoming information effectively.

Many modern organizations choose scalable cloud-based platforms from major providers to host their primary data science operations and storage needs. These virtual services provide incredibly flexible computing power that scales up or down based on your immediate analytical project requirements and budget. Establishing strict data governance protocols early prevents massive data quality issues from compromising your final statistical outputs and business insights. Cloud computing also facilitates better global collaboration by allowing distributed teams to access the same datasets and computing resources simultaneously from any location.
You must also carefully consider the specific software tools and libraries your analysts need to perform their daily tasks effectively and efficiently. Standardizing your internal software stack reduces technical friction when multiple team members collaborate on complex predictive models or data pipelines. Integrating modern version control systems like Git helps track iterative code changes and prevents catastrophic losses of critical analytical progress during development. Furthermore, automated ETL (Extract, Transform, Load) processes ensure that your data scientists spend less time cleaning data and more time generating high-value insights for the company.
How to Start Your Data Science Workflow
Define the Analytical Problem
Work closely with business stakeholders to translate their operational challenges into clear mathematical objectives and measurable KPIs.
Tip: Draft a formal charter document to align everyone on the project goals, success metrics, and expected timeline.
Process and Clean Information
Remove duplicates, handle missing values, and standardize formats across your entire integrated dataset to ensure high data quality.
Tip: Automate your cleaning pipelines using Python scripts to save time when refreshing the information for future analysis.
Train and Validate Models
Feed your prepared information into statistical algorithms and measure their predictive accuracy against holdout datasets to prevent overfitting.
Artificial Intelligence and Deep Learning: The Evolution of Data Science
Artificial intelligence has fundamentally changed how technical professionals approach complex analytical business problems in the modern corporate workplace. Generative AI tools now assist junior analysts with writing complex code, cleaning messy datasets, and generating preliminary statistical reports in seconds. This intelligent automation frees up highly valuable time for strategic human thinking and complex mathematical problem-solving initiatives that drive innovation. Deep learning, a sophisticated subset of AI, has also revolutionized fields like image recognition, natural language processing, and autonomous systems.
The rise of Large Language Models (LLMs) has introduced new ways for organizations to interact with their internal data repositories. By using natural language processing, employees can query complex databases using plain English rather than writing intricate SQL statements. This democratization of data allows non-technical staff to gain insights quickly, further embedding a data-driven culture across all departments. However, the integration of these AI tools requires a robust understanding of prompt engineering and model fine-tuning to ensure the outputs are accurate and relevant to the specific business context.
Despite these incredible technological advancements, human oversight remains a highly critical component of the entire analytical process and data lifecycle. Computer algorithms can process complex information rapidly, but they completely lack the ethical reasoning required for sensitive business decisions and social impact. You must validate statistical model outputs constantly to prevent dangerous algorithmic bias from harming your vulnerable customers or skewing results. Human-in-the-loop systems ensure that AI recommendations are grounded in reality and aligned with organizational values and legal requirements.
The Harvard Business Review notes that a successful data-driven culture requires absolute trust in both the technology and the humans managing it. Engineering teams must document their statistical methodologies clearly so business stakeholders understand how models arrive at specific conclusions or predictions. Total transparency builds the confidence necessary for corporate executives to act boldly on algorithmic recommendations in high-stakes environments. As AI continues to evolve, the role of the data scientist will shift more toward model governance, strategic oversight, and ethical implementation.
️Warning
Always ensure your training data is representative of the real-world population to avoid skewed results and poor generalization. Algorithmic bias can lead to discriminatory outcomes that damage your brand reputation, customer trust, and legal standing.
The Data Scientist Career: Essential Skills for Modern Analysts
The role of a data scientist has evolved into a multi-faceted position that requires a unique blend of technical mastery and soft skills. Beyond proficiency in Python and SQL, modern professionals must master data visualization to tell compelling, persuasive stories with complex information. Being able to explain a complex neural network’s output to a marketing manager is just as important as building the model itself in a laboratory. Collaboration skills are also paramount, as data scientists often work in cross-functional teams alongside product managers, designers, and software engineers.
Continuous learning is another non-negotiable trait for anyone entering the field of data science or big data analytics today. The technology stack changes almost monthly, with new libraries, frameworks, and cloud services emerging to solve niche analytical problems more efficiently. Successful analysts dedicate time each week to exploring new machine learning techniques and staying updated on industry trends through research papers and conferences. This commitment to professional development ensures that their skills remain relevant in a highly competitive and rapidly shifting global job market.
Furthermore, the ability to manage the “MLOps” (Machine Learning Operations) lifecycle is becoming an increasingly sought-after skill in the enterprise. This involves not just building a model, but ensuring it can be deployed, monitored, and retrained automatically as new data becomes available. Understanding the principles of software development, such as CI/CD pipelines and containerization with Docker, allows data scientists to work more effectively with IT operations teams. As the field matures, the distinction between a data scientist and a machine learning engineer continues to blur, requiring a broader technical repertoire.
Data Governance and Ethics: Ensuring Privacy in Data Science
As organizations collect more personal information than ever before, the importance of data ethics and privacy has reached an all-time high. Data scientists must navigate a complex landscape of global regulations, including GDPR in Europe and CCPA in California, to ensure full compliance. Ethical data usage goes beyond legal requirements; it involves considering the long-term societal impact of predictive modeling and automated decisions on individuals. Establishing a strong data governance framework helps organizations maintain high standards of integrity, transparency, and accountability across all analytical projects.
Privacy-preserving techniques, such as differential privacy and federated learning, are becoming standard practice in many high-tech and healthcare industries. These advanced methods allow analysts to extract valuable insights from datasets without ever exposing the sensitive personal information of individual users. By prioritizing privacy, companies can build deeper trust with their customers and avoid the catastrophic financial and reputational fallout of data breaches. Ethical considerations should be integrated into the very beginning of the data science lifecycle rather than treated as a secondary afterthought or a checkbox.
Conclusion and Future Outlook
Data science has firmly established itself as the most critical driver of innovation, efficiency, and growth in the modern business world. From optimizing global supply chains to protecting consumers from financial fraud, the applications of this discipline are virtually limitless and ever-expanding. As artificial intelligence and machine learning continue to mature, we can expect even more sophisticated tools to emerge for processing and interpreting big data. Organizations that embrace a data-driven culture today will be the ones leading their respective industries and defining the markets of tomorrow.
The future of data science lies in the seamless integration of human intuition, domain expertise, and machine intelligence. While algorithms will handle the heavy lifting of data processing and pattern recognition, humans will remain essential for setting strategic direction and ensuring ethical standards. By investing in robust infrastructure, essential skills, and ethical frameworks, businesses can unlock the full potential of their information assets for years to come. The journey toward becoming a truly data-centric organization is ongoing, but the rewards for those who succeed are substantial, enduring, and transformative.

{kind=link}